Home
Homeデータから学ぶ~情報検索とデータマイニングの研究
情報コミュニケーション工学講座 情報計画学研究室
森 本 康 彦
情報を制する者が勝つ
情報を収集し分析することは、ビジネス、科学、スポーツ、政治、果ては芸術に至るまで人間の知的活動を成功させる鍵です。
「情報」といえばなにかすぐに役立つ形で与えられるもののように思えますが、実際,突き詰めれば最終的にはビット列で表されるデータの集まりに過ぎず、そこからどのような意味を汲み取るかは人によってあるいは文脈によって大きく異なります。そこで情報を有効に利用するためにはまずデータを収集し、それを人間が解釈しやすい表現に変換する必要があります。コンピュータは昔からこのデータの収集とその整理・集約のための有用な道具として利用されてきました。
近年、バーコードリーダーなどのデータ収集技術、大容量ハードディスク装置などのデータ格納技術の発展にともない容易にデータベースが構築できるようになりました。構築されたデータベースから、地域別売上、店舗別売上、商品別売上、月次売上などの各軸(次元)で集計したり、さらには店舗および商品別売上のような任意の軸(次元)の組み合わせに対して集計したりできます。このような分析を多次元分析と呼び、この分析結果をグラフなどの形式に表示することで傾向やパターンを知ることが可能になっています。このようにして得られる情報は人間が意志決定を行う際に利用されています。
身近な例をあげるとコンビニに陳列される商品は、地域や季節ごとの詳細な売れ行きを分析したうえで決定されています。他にも、プロ野球での守備位置、投手の配球、作戦なども現在ではコンピュータを使った多次元分析の結果を参考に決定されているのです。(スポーツデータ分析最大手の「データスタジアム(株)」のホームページhttp://www.datastadium.co.jp/は多次元分析とその視覚化のイメージをつかむ意味で参考になります。)
大規模データからの知識発掘
90年代中盤までは多次元分析をいかに効率的に実現するかがデータベース技術の主要な研究テーマでしたが、上述したように、コンピュータの記憶装置には以前に増して大量で多様なデータが、日常の業務の結果として蓄えられるようになってきました。それにともない、大規模なデータに特化した計算技術や、情報を単なる集計結果ではなくもっと踏み込んだ表現(知識)に変換する技術への要求が高まるようになってきました。データマイニングとは、そのような大規模なデータに対する知識発見技術を指します。データマイニングの「マイニング」とは採鉱するという意味で、文字通り山のようなデータから価値ある情報を掘り出そうというわけです。
そのような、データマイニング技術の代表的なものをあげると、ビールを購入した顧客はおむつも購入する頻度が高いなど併買商品の相関を発見する「相関ルール発見機能」、ビールを購入した顧客が、その後、ブランデーを購入する頻度が高いといった「時系列パターン発見機能」、ある商品の購入実績があるかないかといったカテゴリー化されたラベル、または、購入金額など連続数値型のラベルをもつデータを、決定木・回帰木などにより分類し、判別ルールを生成する「クラス分類機能」、グループ内の各データが互いに類似しているようなグループ分けをする「クラスタ生成機能」などがあります。インターネットショッピングをする際に、よくおすすめ商品を提示されることがありますが、そこには、マイニング技術で発見された知見が使われているのです。
インターネット検索最大手Googleの創業者サーゲイ・ブリン氏は、Google創業時はスタンフォード大学でデータマイニングを研究する大学院生でした。(ちなみに彼の論文には我々の論文が引用されています。)ウェブページのランキング技術としてよく知られているGoogleの中核技術である「PageRank」は、大量のウェブページのリンク情報から、「より多くのよいページからリンクされているページ」を価値のあるページとして取り出すマイニング技術です。
時空間データマイニング
私の研究室で近年、とくに時間情報、空間情報を含むデータからのデータマイニング技術の研究開発に力を入れています。
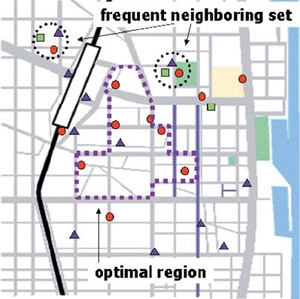
図1は我々の開発した位置情報パターン発掘アルゴリズムの出力例です。
地図上で赤点○、青点△、緑点□は、それぞれ携帯電話の時刻表、チケット注文、天気予報のサービスにアクセスした記録と仮定します。「frequentneighboringset」と示されるパターは「互いに近接して発現する」頻出パターンを示しています。たとえば、赤点○、青点△、緑点□の3組が互いに近いというパターンが頻出していた場合、例えば時刻表、チケット注文、天気予報のサービスは互いに近くでアクセスされるといったことを知ることができます。このような知見があれば、時刻表とチケット注文がアクセスされる場所で天気予報に関するプッシュ型コンテンツや広告を戦略的に配信することができます。
データの提供元との契約上、実際の解析結果を本稿でそのまま紹介することはできませんが、例えばチェーン店を展開する企業で、売り上げの良い店舗、売り上げの悪い店舗の近所にはどんな施設があるといった形式のパターンをこの技術を使って発掘できます。
地図中で「optimalregion」と示されるものも、位置情報に関連して発掘されるパターンの例です。たとえば、犯罪や交通事故の発生地点がデータベース化されていた場合、地図上で犯罪や交通事故の密度を最大化する領域を算出する高速なアルゴリズムも開発しています。たとえば、図の「optimalregion」と示される領域が犯罪発生密度の高い領域だった場合、そこを重点的に警備したり、その地域に入る際にとくべつに注意を払ったりという対策をとれるほか、この領域内にどんな施設がどれだけ含まれているかといった分析を進めることもできます。
時間情報に関する技術としては、時系列の数値データから値の増減パターンを発掘する技術を開発しています。図2は、あるチェーン店の数年間の商品ごとの売り上げ記録を時系列データとして解析した結果です。(各パターンには具体的な商品名(会社名、商品名、ブランド名)が入るのですが、本稿では抽象的な商品名に変更しています。)このマイニング技術で「売上増となった商品は、翌週、売上が減少」、「ドレッシング売上増の翌週、お茶の売上減」といった時間を含む知見が発見されました。前者は、潜在需要の先食いといった一見すればあたりまえのパターンですが、逆の売上減の翌週、増というパターンがなかった点とあわせると経営者にとってとても参考になったようです。つまり、安易に特売でたくさん売ると、翌週、以降売り上げが減少し、その減少分はなかなか戻らないと解釈できるのです。後者は、寒い時期から暖かくなる過程で、顧客はサラダを食べる機会を増やし、(温かい)お茶を飲む機会を減らすよう生活スタイルを変えているという知見に結びついています。筆者はこの分析技術で経営科学系研究部会連合協議会という産学協同の組織が主催するデータ解析コンペティションで「審査員特別賞」を受賞しています。 これらの成果をふまえ、現在は移動体情報などに応用すべく時空間両方にかかわるマイニング技術の研究に取り組んでいます。